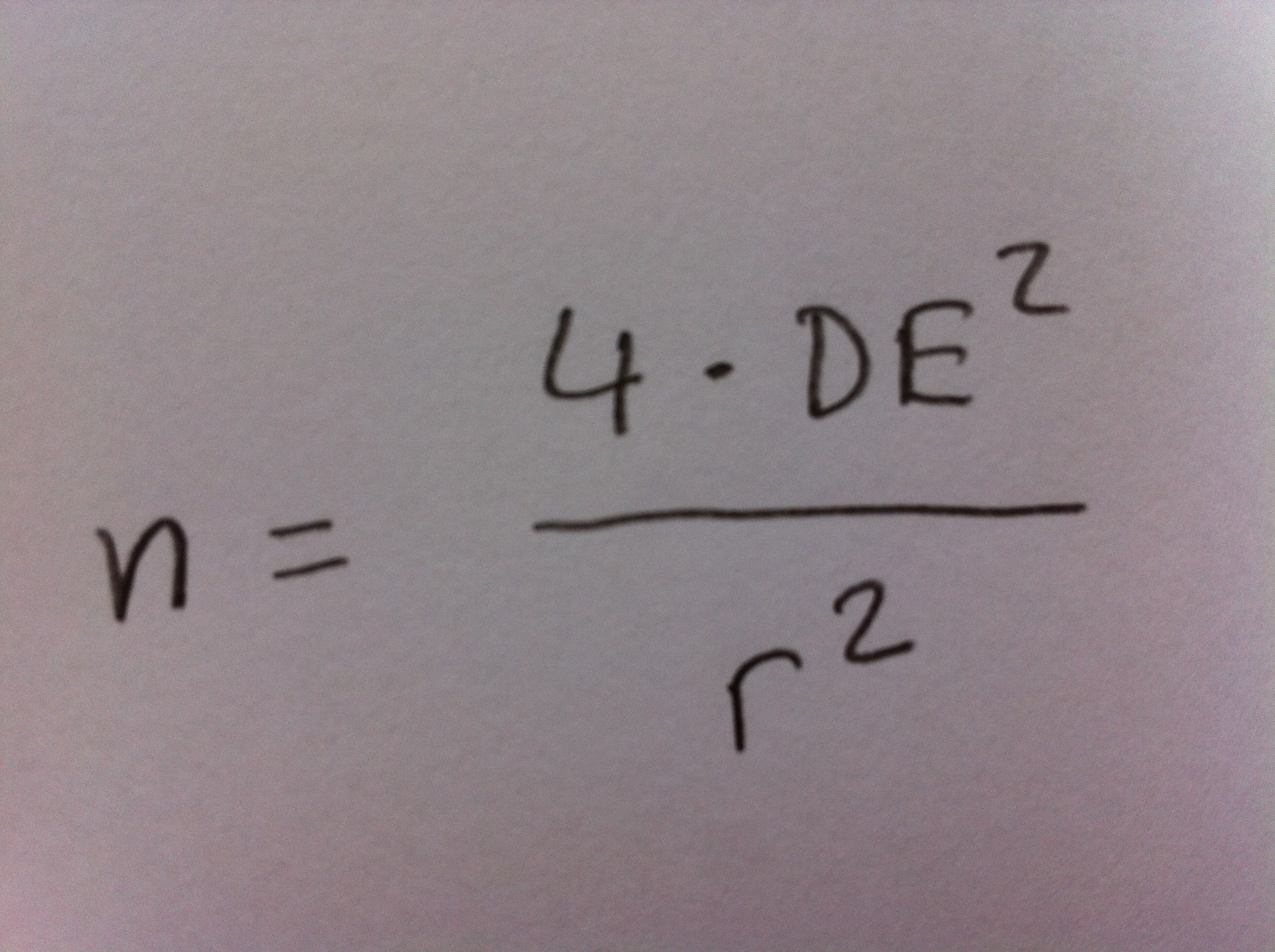1. ¿Cuál de las siguientes afirmaciones es cierta si hemos realizado un ANOVA de dos factores cruzados y tenemos una p=0.1 para el primer factor, una p=0.03 para el segundo factor y una p=0.01 para la interacción?
a. Hay diferencias significativas entre los niveles del primer factor, hay diferencias significativas entre los niveles del segundo factor y no hay interacción entre los dos factores.
b. Hay diferencias significativas entre los niveles del primer factor, hay diferencias significativas entre los niveles del segundo factor y hay interacción entre los dos factores.
c. No hay diferencias significativas entre los niveles del primer factor, no hay diferencias significativas entre los niveles del segundo factor y no hay interacción entre los dos factores.
d. No hay diferencias significativas entre los niveles del primer factor, hay diferencias significativas entre los niveles del segundo factor y hay interacción entre los dos factores.
2. ¿Cuál de las siguientes presentaciones de la Odds ratio es incoherente?
a. OR=0.33 IC 95% (0.01, 0.6) p=0.001
b. OR=0.1 IC 95% (0.01, 0.6) p=0.13
c. OR=4.2 IC 95% (1.5, 15.3) p=0.02
d. OR=0.5 IC 95% (0.3, 1.7) p=0.53
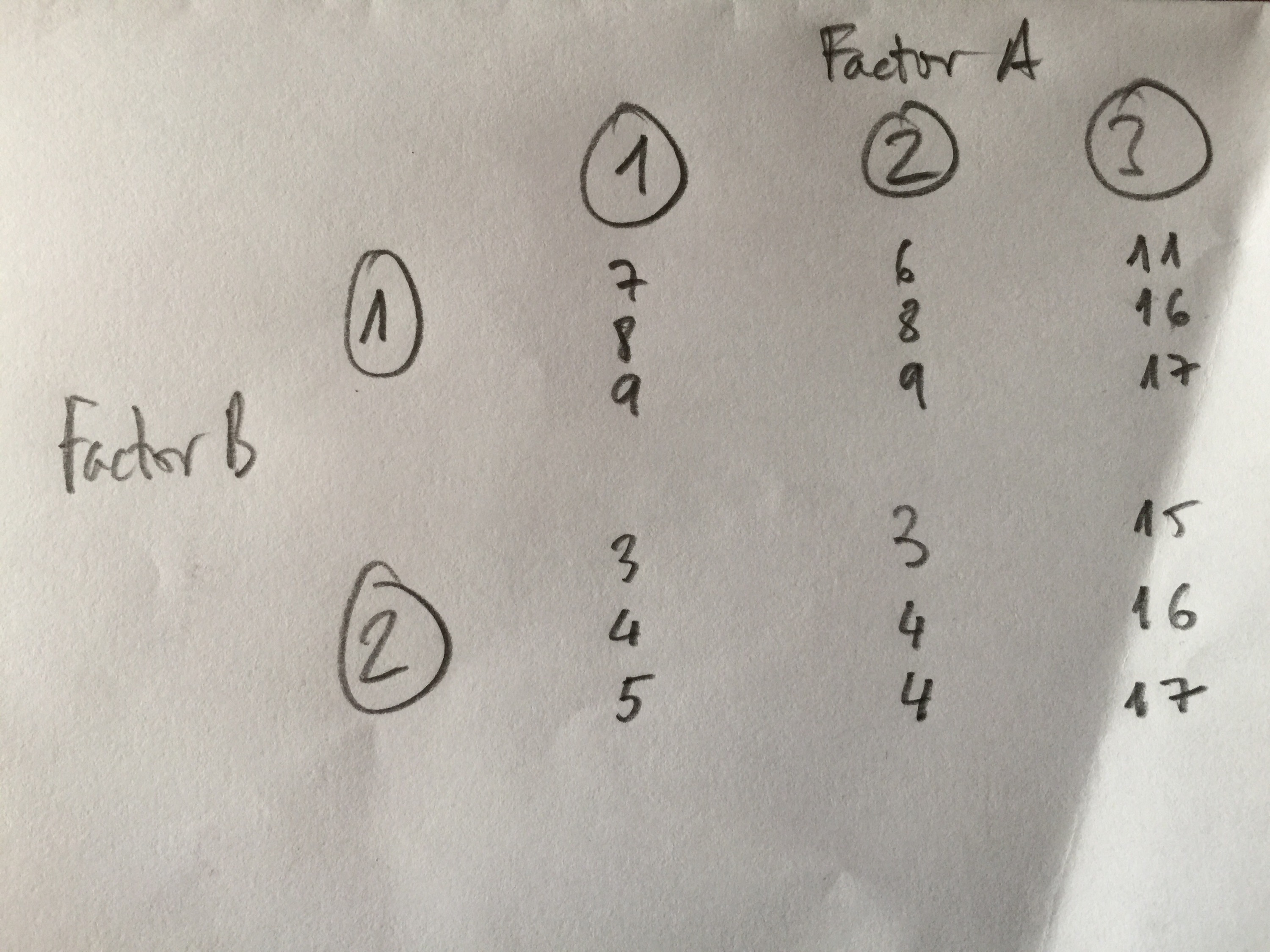
3. En un estudio clínico con los siguientes datos, ¿cuál es la afirmación cierta?

a. El p-valor del Factor A en un ANOVA de dos factores será menor de 0.05, el del Factor B será mayor que 0.05 y el p-valor de la interacción será menor que 0.05.
b. El p-valor del Factor A en un ANOVA de dos factores será mayor de 0.05, el del Factor B será menor que 0.05 y el p-valor de la interacción será mayor que 0.05.
c. El p-valor del Factor A en un ANOVA de dos factores será menor de 0.05, el del Factor B será menor que 0.05 y el p-valor de la interacción será mayor que 0.05.
d. El p-valor del Factor A en un ANOVA de dos factores será mayor de 0.05, el del Factor B será mayor que 0.05 y el p-valor de la interacción será mayor que 0.05.
4. Se están comparando dos tratamientos a pacientes con trastorno bipolar. La variable analizada es la concentración de un determinado neurotransmisor. El tamaño de muestra es de 50 personas. Todas ellas toman ambos tratamientos en distintas épocas pero siempre durante un periodo depresivo. La técnica adecuada al caso es:
a. Un test de proporciones.
b. Un test de McNemar.
c. Un test exacto de Fisher.
d. Ninguna de estas tres anteriores.
5. ¿Cuál de las siguientes muestras tiene un percentil 60 igual a 10?
a. (0, 0, 9, 9, 9, 9, 10, 20, 20, 20)
b. (0, 9, 9, 9, 9, 9, 11, 11, 11, 20)
c. (0, 0, 0, 9, 9, 10, 12, 13, 14, 20)
d. (9, 9, 9, 10, 10, 10, 11, 11, 13, 29)
6. Si la relación entre dos variables la podemos representar mediante una regresión lineal simpe con una R2=81%, ¿cuál de las siguientes afirmaciones es cierta?
a. Existe una correlación significativa entre las variables.
b. La correlación de Pearson es de 0.9.
c. Si la relación es significativa, cosa que no podemos afirmar con la información que tenemos, se trata de una muy débil determinación la que hay entre una y otra variable.
d. La regresión no sabemos si es o no significativa pero sí sabemos que la correlación es negativa entre las dos variables.
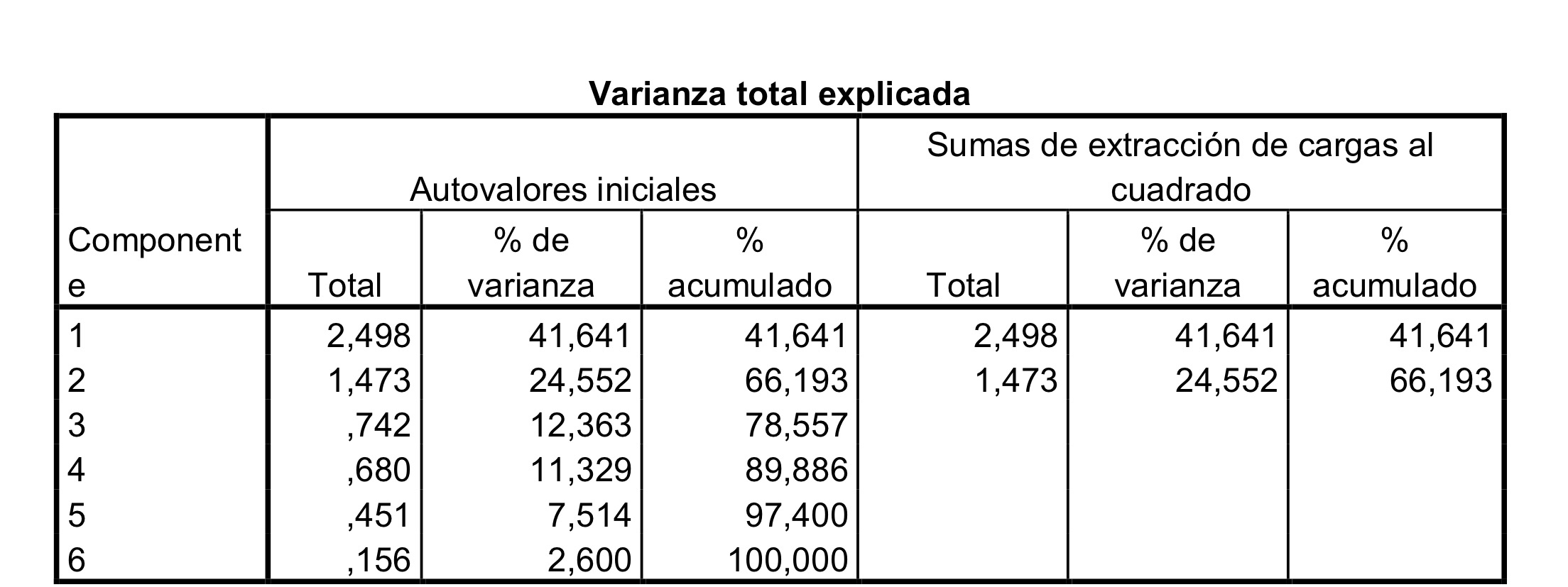
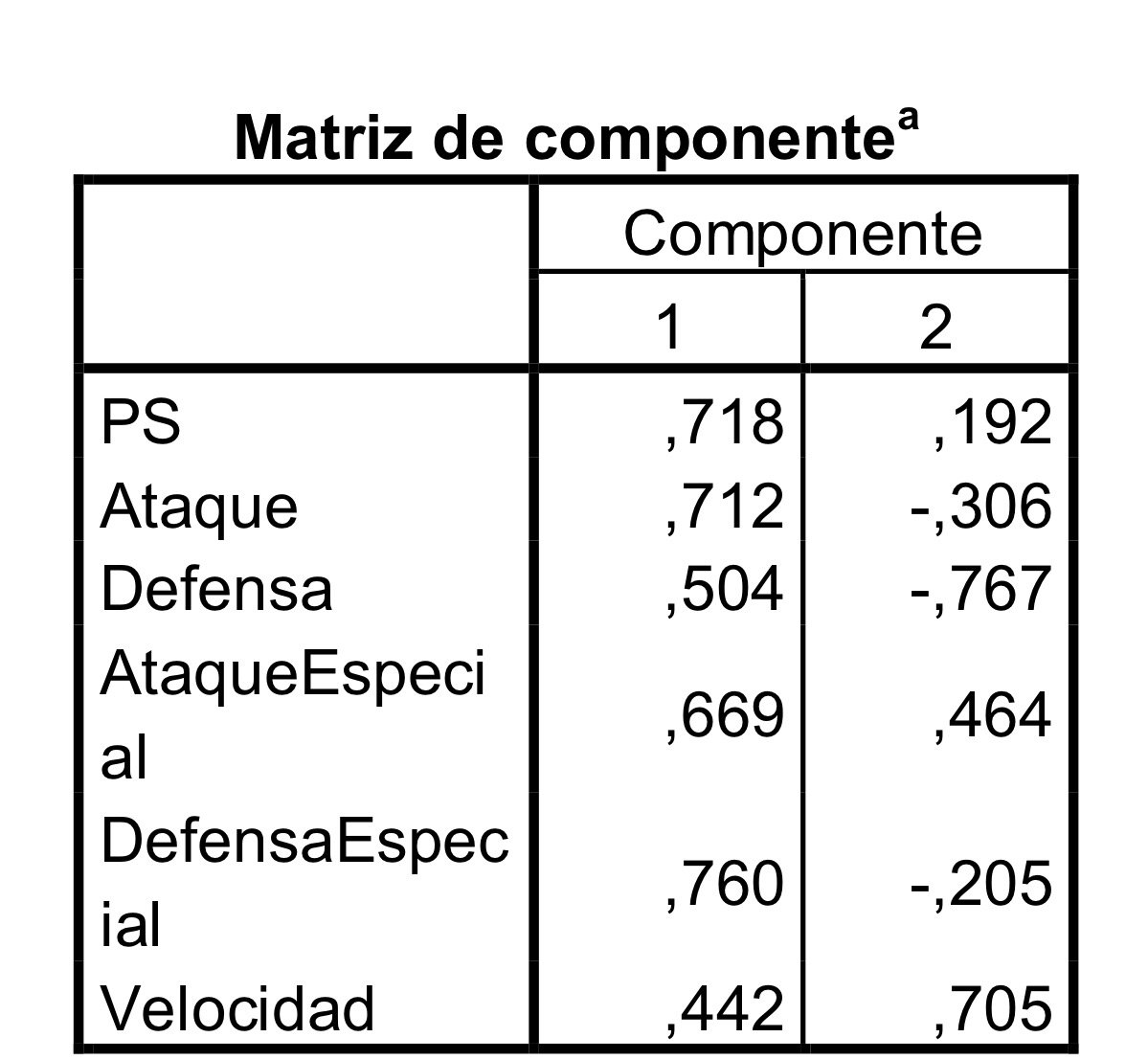
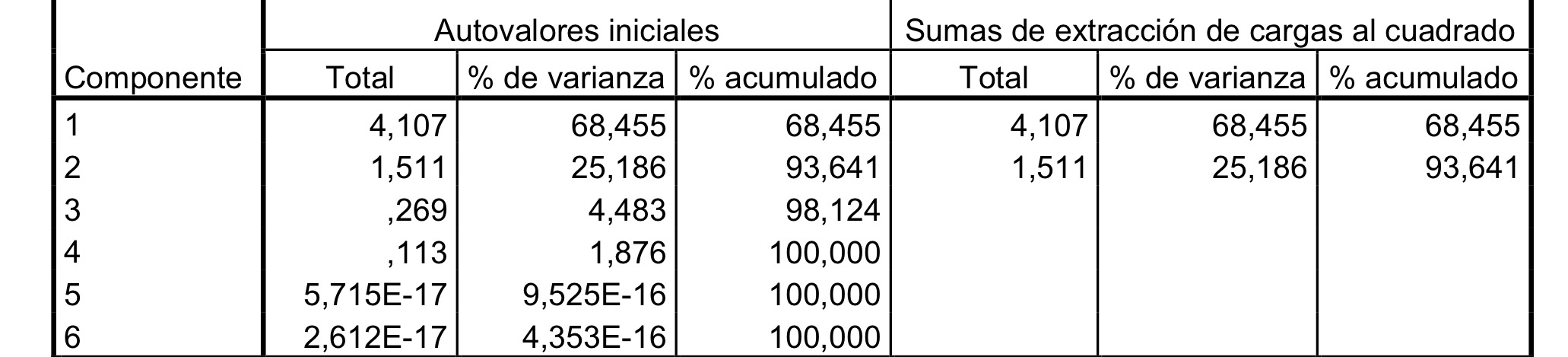
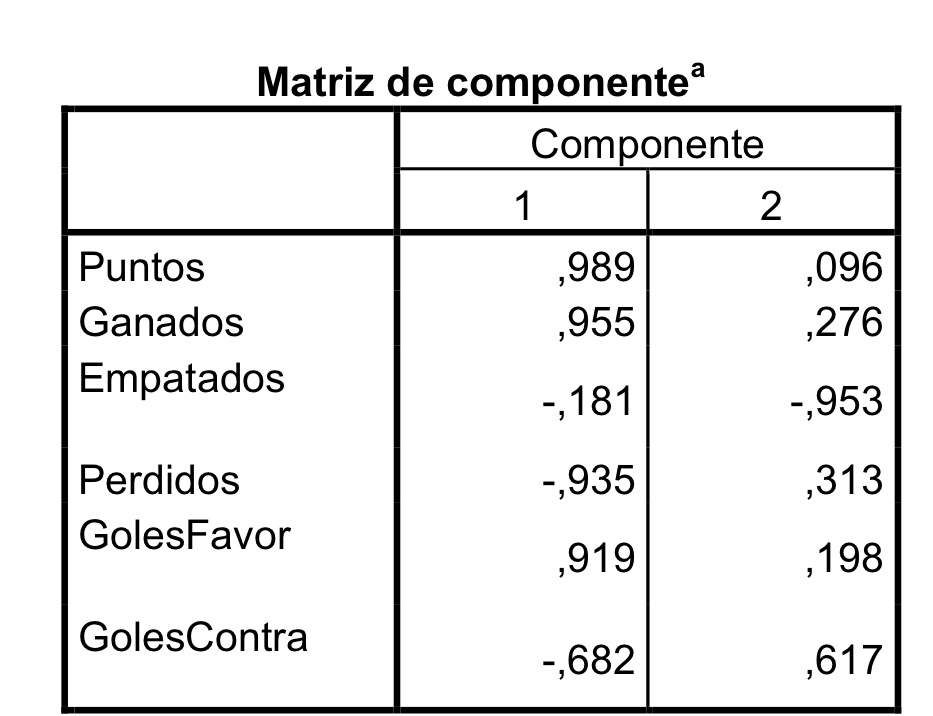
7. Si en un Análisis de componentes principales tenemos como primer componente la variable Y1=0.5X1+0.5X2+0.5X3+0.5X4+0.5X5, ¿qué afirmación cierta?:
a. Un individuo con los valores (0, 1, 1, 1, 1) de las cinco variables originales tendrá un valor de 1 para la primera componente.
b. Existe una débil correlación entre las cinco variables originales del estudio.
c. Un individuo con los valores (1, 1, 1, 1, 1) de las cinco variables originales tendrá un valor de 2.5 para la primera componente.
d. Un individuo con los valores (1, 1, 1, 1, 0) de las cinco variables originales tendrá un valor de 1 para la primera componente.
8. Tenemos un IC del 95% de la media que es (20, 22), ¿qué afirmación es cierta?
a. El tamaño de muestra es 200.
b. La desviación estándar es 1.
c. Si la desviación estándar es 10 el tamaño de muestra es 400.
d. Un intervalo de confianza del 99.5% sería (19, 23)
9. ¿Qué tamaño de muestra necesitamos tener para estimar la media poblacional del Mini-Mental en el diagnóstico de pacientes con Alzhéimer si sabemos, a partir de una muestra piloto, que la Desviación estándar es, aproximadamente, 0.2 y queremos tener un intervalo de confianza de una precisión establecida con un radio de 0.1?
a. 160
b. 1600
c. 16
d. 16000
10. Si comparamos el Mini-Mental al año y a los dos años del diagnóstico en 100 pacientes con Alzhéimer para comprobar si ha habido un descenso significativo en el nivel de esta variable y aplicamos un test de Shapiro-Wilk a las restas de los valores, paciente a paciente, obteniendo un p-valor de 0.001, debemos aplicar:
a. El test de la t de Student de varianzas iguales.
b. El test de los signos o el test de Wilcoxon. Cualquiera de los dos es aceptable en este caso.
c. El test de la t de Student de datos apareados.
d. Debemos comprobar la igualdad de varianzas con el test de Fisher-Snedecor. Si el p-valor de este test es mayor que 0.05 debemos aplicar el test de la t de Student de varianzas iguales, si el p-valor es menor que 0.05 debemos aplicar el test de la t de Student de varianzas desiguales.
11. Queremos comparar el nivel de conocimientos de estudiantes de Psicología de dos universidades distintas justo al final de sus estudios. Para ello realizamos un test a 40 alumnos de cada una de esas dos universidades. Las medias muestrales son 6 y 7, respectivamente. Las desviaciones estándar son 1.5 y 1.65, respectivamente. Aplicamos un test de Shapiro-Wilk a cada una de las dos muestras y tenemos los siguientes p-valores: 0.3 y 0.1, respectivamente. El test de Fisher-Snedecor de comparación de varianzas tiene un p-valor de 0.007. La técnica adecuada al caso será:
a. El test de la t de Student de datos apareados.
b. El test de Mann-Whitney.
c. El test de la t de Student de varianzas iguales.
d. El test de la t de Student de varianzas desiguales.
12. Si tenemos dos muestras independientes de dos poblaciones a las que hemos aplicado correctamente un test de la t de Student de varianzas iguales con un p-valor de 0.04 y una potencia del 90%, ¿cuál de las siguientes afirmaciones es cierta?:
a. No tenemos suficiente potencia.
b. Para afirmar que hay diferencias a nivel poblacional, con máximo nivel de fiabilidad, necesitamos tener una potencia del 99%.
c. Podemos afirmar ya, a partir del p-valor y de la potencia, que hay diferencias entre ambas poblaciones comparadas.
d. Debemos aumentar el tamaño de muestra hasta que el p-valor sea mayor que 0.05.
13. Si hemos calculado la V de Crámer entre dos variables cualitativas y resulta ser un valor de 0.5 podemos afirmar:
a. Es una relación estadísticamente significativa.
b. Podemos crear una regresión lineal simple entre estas dos variables.
c. Para evaluar la significación de la relación necesitamos hacer un test de la ji-cuadrado.
d. Se trata de una relación directa por ser un valor positivo el de la V de Crámer.
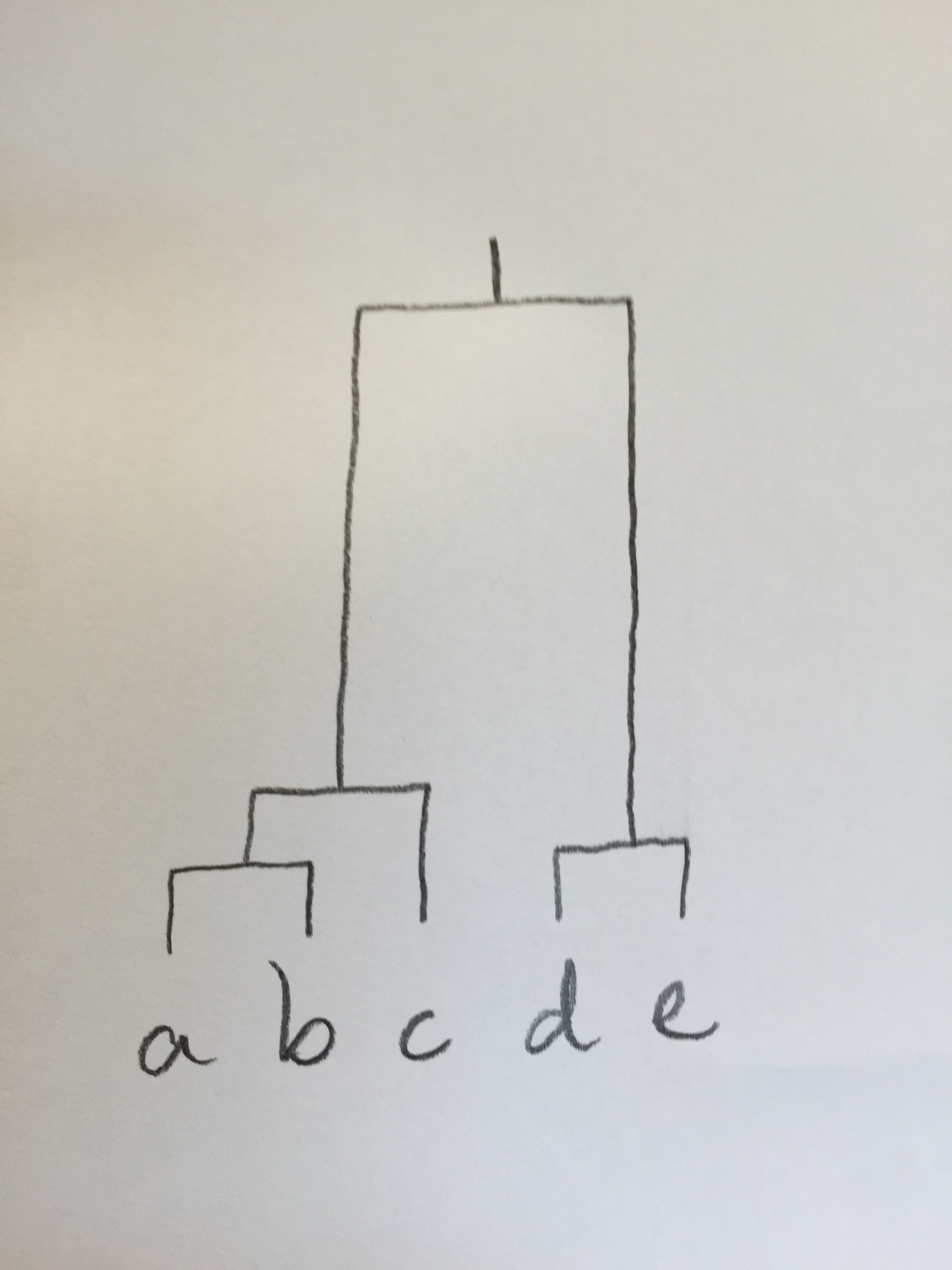
14. Si tenemos una muestra de cinco pacientes (a, b, c, d, e) a los que les hemos medido una única variable cuantitativa y de la cual tenemos el siguiente dendrograma, obtenido mediante un Análisis clúster:

¿Cuál de las siguientes muestras no está razonablemente asociada a este análisis?:
a. (5, 6, 8, 50, 51)
b. (500, 503, 490, 150, 151)
c. (50, 51, 53, 5, 6)
d. (50, 51, 70, 80, 90)
15. Un intervalo de confianza del 95% de la media con media muestral de 100, con desviación estándar de 45 y tamaño muestral de 9 es el siguiente:
a. (97, 103).
b. (94, 106).
c. (85, 115).
d. (70, 130).
16. Si en una tabla de contingencias 2×2 en la que relacionamos dos variables cualitativas tenemos que el valor de la ji-cuadrado es 2.6 podemos afirmar:
a. Que estamos ante una relación no significativa porque el valor 2.6 es inferior al valor de referencia máximo aceptable para mantener la hipótesis nula en las tablas 2×2.
b. Que es imposible saber la significación porque no podemos saber si el p-valor es mayor o menor que 0.05.
c. Que el valor de la ji-cuadrado no nos dice nada sobre la significación de esa relación.
d. No es una relación significativa porque el valor 2.6 es un valor suficientemente próximo a cero.
17. ¿Cuál de las siguientes afirmaciones no es cierta respecto a la V de Crámer?
a. Es una medida del grado de relación entre dos variables cualitativas.
b. Es un valor que está entre 0 y +1.
c. Tiene sentido calcularla tras una ji-cuadrado con p>0.05.
d. Puede calcularse a cualquier tabla de contingencias.
18. ¿Cuál de las siguientes afirmaciones no es cierta?:
a. El error estándar siempre es menor o igual a la desviación estándar en el estudio de una variable.
b. Una correlación de Pearson no puede aplicarse a la relación entre variables cualitativas.
c. Una V de Crámer nunca puede ser negativa.
d. Un valor de ji-cuadrado negativo implica una relación inversa entre las variables estudiadas.
19. ¿Cuál de las siguientes afirmaciones es cierta?
a. La mediana de una muestra siempre es igual al primer cuartil.
b. Una Odds ratio de 2.5 con un intervalo de confianza del 95%: (0.45, 7.18) indica que estamos ante un factor de riesgo significativo porque el intervalo no incluye al 0.
c. Si en una muestra de una variable cuantitativa la asimetría estandarizada está dentro del intervalo -2 y 2, entonces podemos describirla perfectamente mediante la media y la desviación estándar.
d. Una correlación negativa irá acompañada de una regresión lineal simple con pendiente negativa.
20. ¿Cuál de las siguientes afirmaciones no es cierta?
a. En un ANOVA de dos factores las comparaciones múltiples de un factor se hacen únicamente si la interacción es significativa.
b. El rango y el rango intercuartílico, en una muestra, pueden ser iguales.
c. Una Odds ratio de 1.75 con un intervalo de confianza del 95%: (1.05, 3.18) indica que se trata de un factor de riesgo estadísticamente significativo.
d. Si en una tabla de contingencias calculamos un valor de ji-cuadrado y es 5.67, la significación de ese valor dependerá del número de filas y columnas de esa tabla.